Nov 18th, ‘20/1 min read
Much That We Have Gotten Wrong About SRE
An illustrated summary of Developers ➡ DevOps ➡ SRE
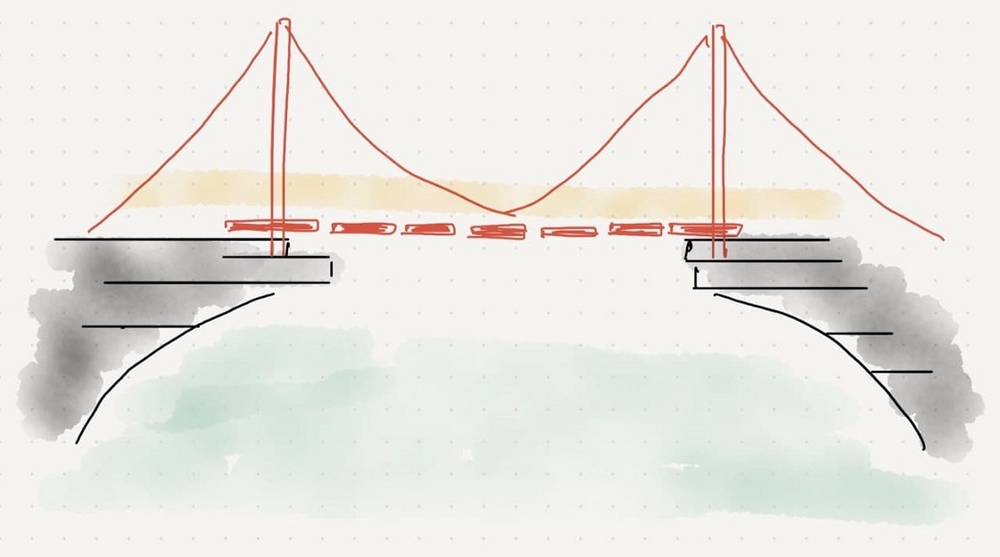
1. Developers wanted to ship their produce
To the other side
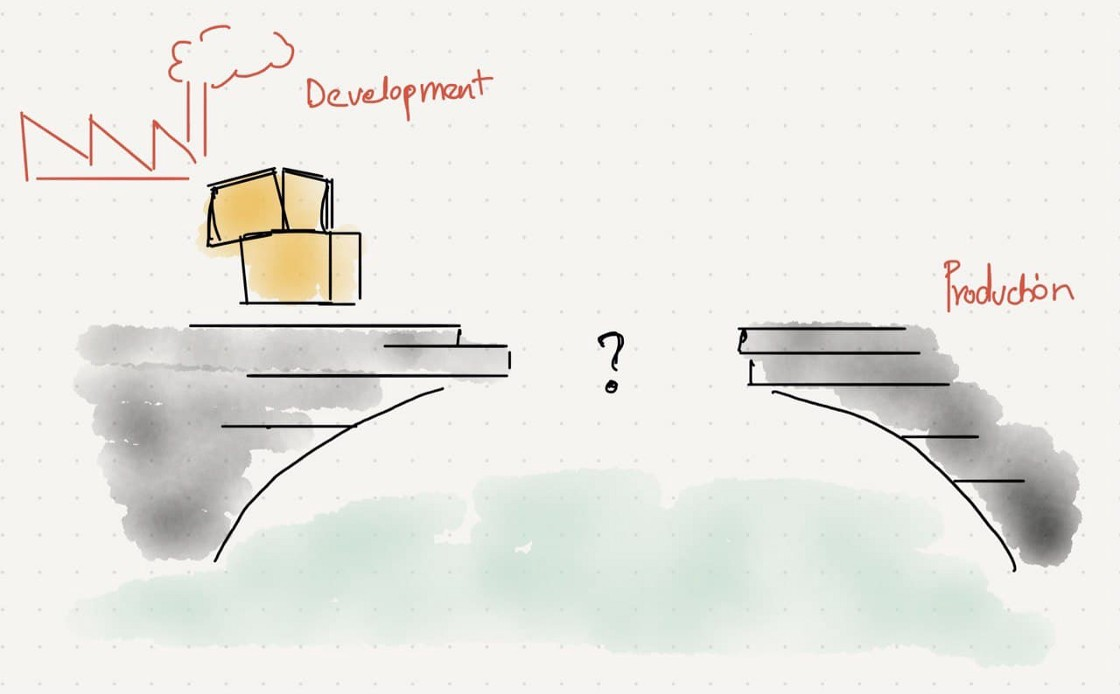
2. Production never matches the development environment. It resembles, but cannot match
So they deployed people on the other side
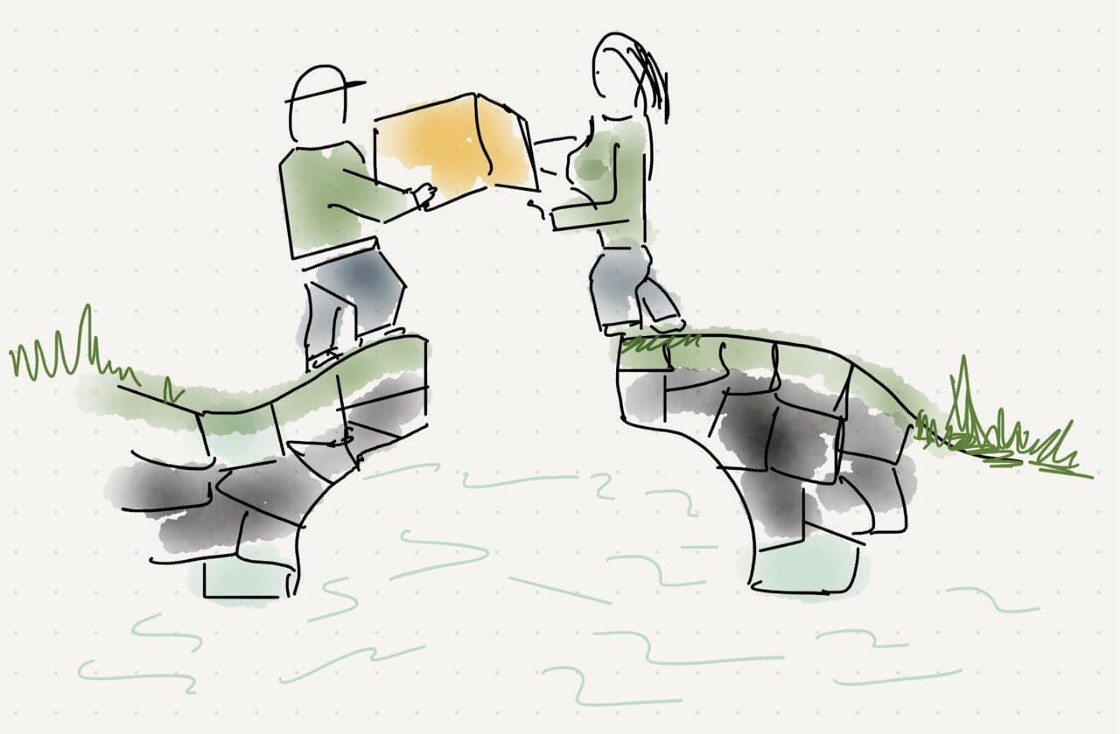
3. But this process was slow, they wanted to deploy faster
So they deployed Continuous-Deployment (CI/CD)
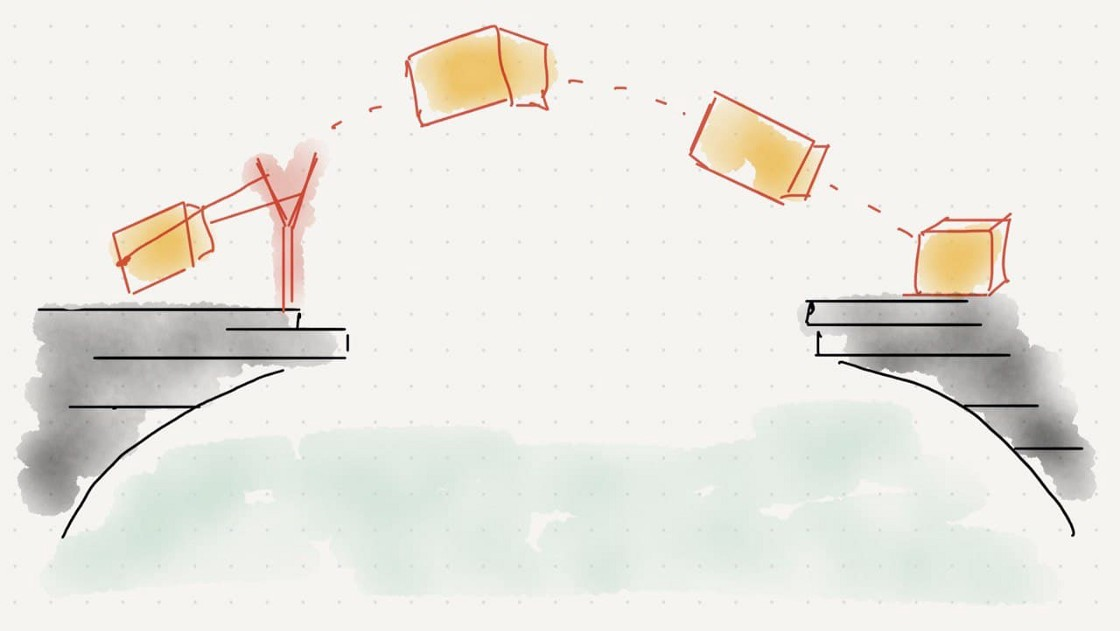
4. To improve reliability, we got SRE to do this
SREs’ first job was to hold this ship, but that’s all where they got stuck at
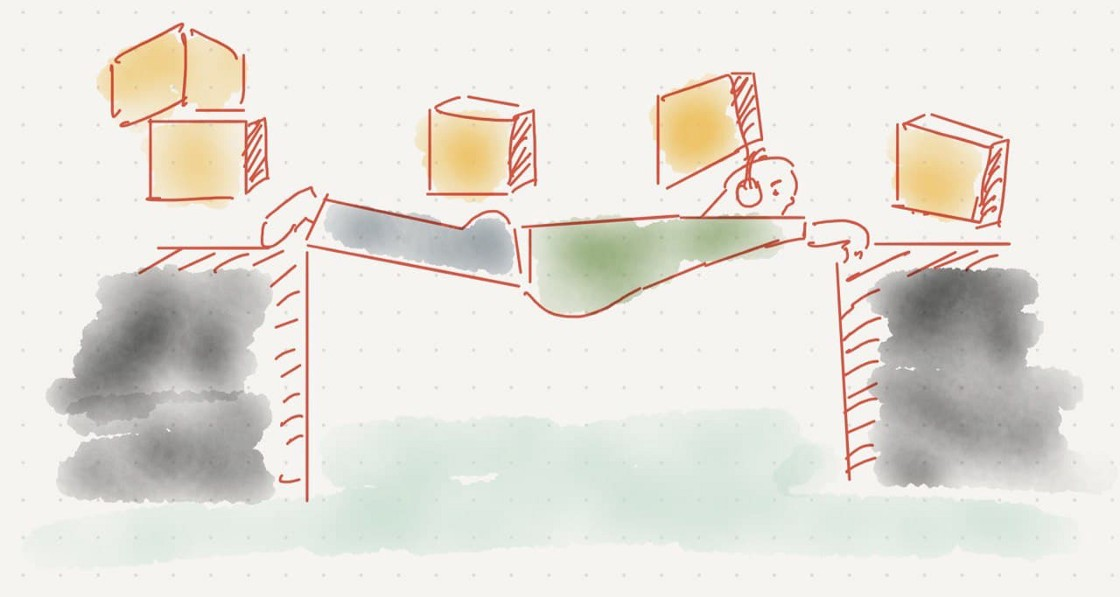
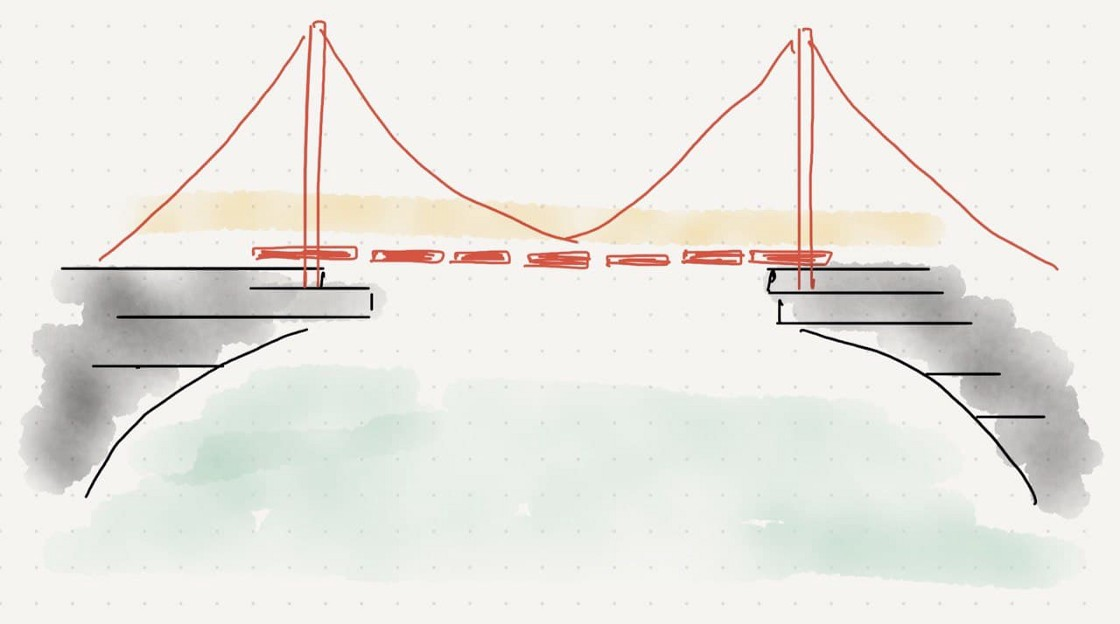
5. What Site Reliability Engineers should’ve built is
SREs should’ve been *engineering* and *observing* the bridge, but instead they became the bridge
Contents
Newsletter
Stay updated on the latest from Last9.
Handcrafted Related Posts

Learnings integrating jmxtrans
JMX metrics give solid insights into the workings of your application. Integrating them with Levitate (our time series data warehosue) required us to jump some hoops with vmagent.
Saurabh Hirani
Self-managed Prometheus vs Managed Prometheus
What are the differences between Self-managed Prometheus vs Managed prometheus? How do you choose what works for you?
Last9

GCP Managed Service For Prometheus vs. Levitate
A detailed comparison of Levitate and Google Managed Prometheus - Cost, Scale and Ease of Use
Prathamesh Sonpatki