All Topics / Observability
Observability

Everything in software monitoring is dead, apparently
Chasing shiny new toys, as always ;)
Aniket Rao

Why your monitoring costs are high
If you want to bring down your monitoring costs, you need to shake up a decision paralysis in engineering
Aniket Rao

Software Observability from the Lens of Radar and a Black Box
Observability is often a misunderstood and misused term. It has come to mean nothing and everything at this point. Read more on how Observability can be viewed from the lens of a Radar and a Black Box.
Nishant Modak

This arctic winter — time to repay your tech debt
We're in a peak tech winter. What should engineering teams focus on when product velocity dwindles?
Ajey Gore
Understanding the Rasmussen model for failures
What does the Rasmussen model teach us about Site Reliability Engineering?
Nishant Modak

How we tame High Cardinality by Sharding a stream
Using 'Sharding' to tame High Cardinality data for Levitate - Our Time Series Data Warehouse
Piyush Verma

Observability vs. Telemetry vs. Monitoring
Observability vs Telemetry vs Monitoring - What they are, differences and what lies in future
Last9

OpenTelemetry for dummies: ELI5
What is OpenTelemetry? Why is it important? Do SREs need to adopt OTel? An Explain It Like I'm 5.
Mohan Dutt Parashar

What is OpenTelemetry Collector
What is OpenTelemetry Collector, Architecture, Deployment and Getting started
Last9

What Site Reliability Engineering needs — A swarm of rogue bees
If all companies are software companies, all companies need better Observability to understand how performative their software is
Aniket Rao

QCon New York 2023 Recap
Recap of QCon New York 2023 Conference
Prathamesh Sonpatki

What is High Cardinality
Overview of what is high cardinality in the context of monitoring using Prometheus and Grafana
Prathamesh Sonpatki
What is OpenTelemetry
Learn what is OpenTelemetry: The open-source observability framework for collecting and processing telemetry data from applications and systems.
Last9

Observability is a practice, not a job
Engineering organizations that ship fast have Observability as part of their core DNA.
Aniket Rao

Understanding Metrics, Events, Logs and Traces - Key Pillars of Observability
Understanding Metrics, Logs, Events and Traces - the key pillars of observability and their pros and cons for SRE and DevOps teams.
Prathamesh Sonpatki

SRE vs Platform Engineering
What's the difference between SREs and Platform Engineers? How do they differ in their daily tasks?
Last9

Streaming Aggregation vs Recording Rules
Streaming Aggregation and Recording Rules are two ways to tame High Cardinality. What are they? Why do we need them? How are they different?
Last9
Prometheus vs Datadog
Comparison between Prometheus and Datadog - two of the most popular monitoring tools in the market today
Last9

What is Prometheus Remote Write
Learn about what is Prometheus Remote Write and how to configure it.
Last9

SRE vs DevOps
What's the difference between SREs and DevOps professionals? How do they differ in their daily tasks?
Last9

High Cardinality for Dummies: ELI5
High Cardinality woes are far & frequent in today's modern cloud-native environment. What does it mean, & why is it such a pressing problem?
Mohan Dutt Parashar

Who should define Reliability — Engineering, or Product?
Whoever owns Reliability should define its parameters. But who owns the Reliability of a Product? Engineering? Product Management? Or the Customer success team?
Piyush Verma

What do self-driving cars tell us about Site Reliability Engineering?
From Robocars to Reliability — SRE with self-driving cars; mapping out where the Observability space is in conjunction with self-driving cars
Mohan Dutt Parashar

Observability—OSS vs Paid vs Managed OSS
The Reliability industry needs a managed, non-vendor lock-in answer to spiraling costs, high cardinality and the toil of managing a tsdb
Satyajeet Jadhav

High Cardinality? No Problem! Stream Aggregation FTW
High cardinality in time series data is challenging to manage. But it is necessary to unlock meaningful answers. Learn how streaming aggregations can rein in high cardinality using Levitate.
Piyush Verma

Recap of SRECon Americas 2023
SRECon is a conference hosted by USENIX and is focused on site reliability, distributed systems, and systems engineering at scale. A Recap of SRECon Americas 2023.
Last9

Understanding “Cricket Scale”
How does a DevOps/Site Reliability Engineer plan for "Cricket scale"? How do you warm systems' about to witness 30+ million concurrent users?
Aniket Rao

Reliability Engineering for Dummies: ELI5
Explaining Reliability Engineering to a 5-year-old.
Mohan Dutt Parashar
Rethinking Anomaly Detection: Focus on business outcomes
From the trenches at Games24x7 — Sanjay, on how Reliability engineering should drive core business metrics
Sanjay Singh

Interesting talks on Observability from Fosdem 2023
A recap of the talks from the Observability and Monitoring dev room at Fosdem 2023.
Prathamesh Sonpatki

Prometheus Alternatives
What are the alternatives to Prometheus? A guide to comparing different Prometheus Alternatives.
Last9
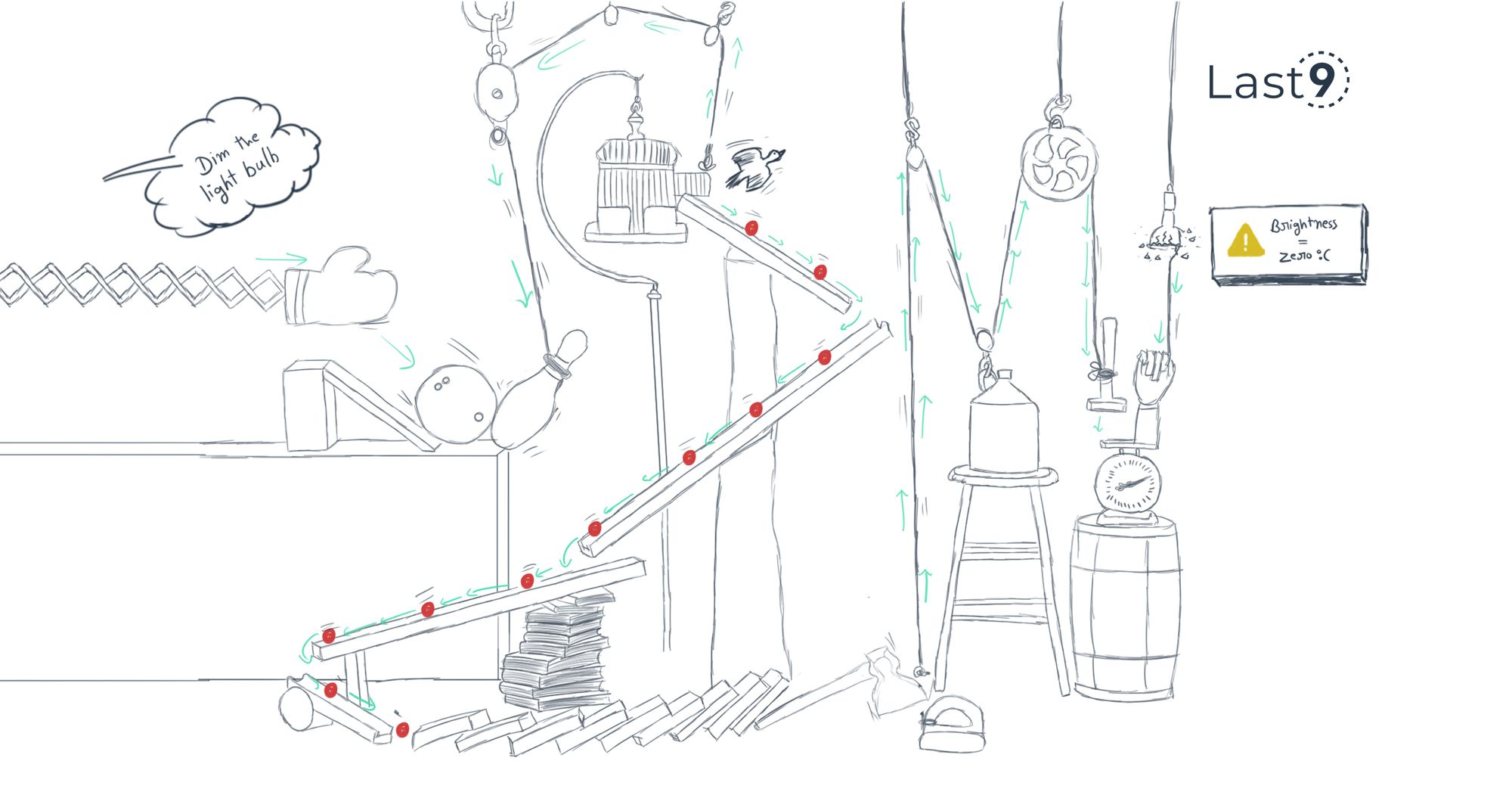
Observability is dead, long live observability
No tool can magically offer you 99.999s. Observability is largely about the basics. And basics are boring. But, boring is hard. Boring is battle tested.
Aniket Rao
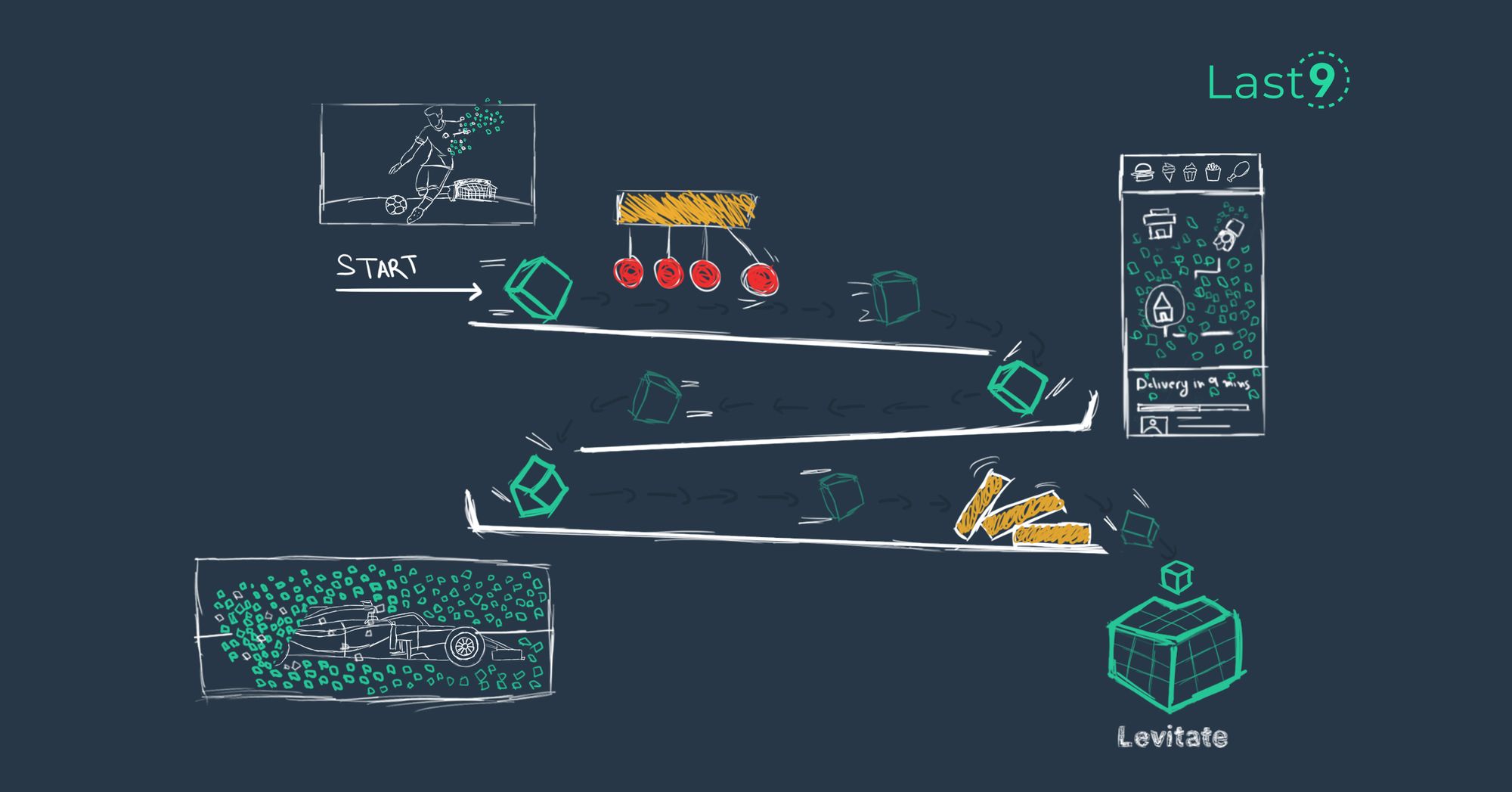
Introducing Levitate: ‘uplifting’ your metrics woes because self-management sucks like gravity
Managing your own time series database is painful. We’ve moved from servers to services, and yet, monitoring metrics data is primitive. Our managed time series database powers mission-critical workloads for monitoring, at a fraction of the cost.
Nishant Modak
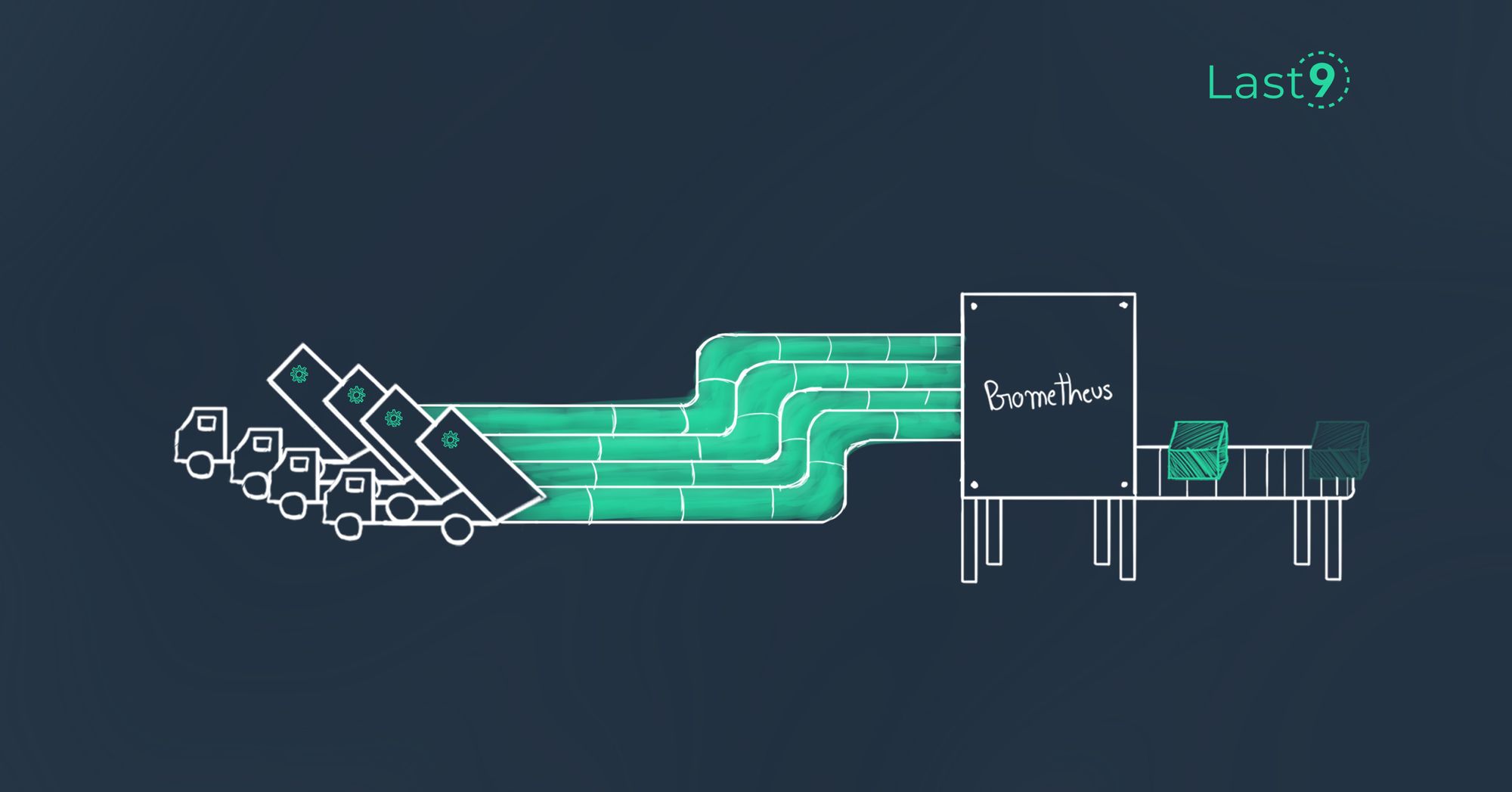
Best Practices Using and Writing Prometheus Exporters
This article will go over what Prometheus exporters are, how to properly find and utilize prebuilt exporters, and tips, examples, and considerations when building your own exporters.
Last9
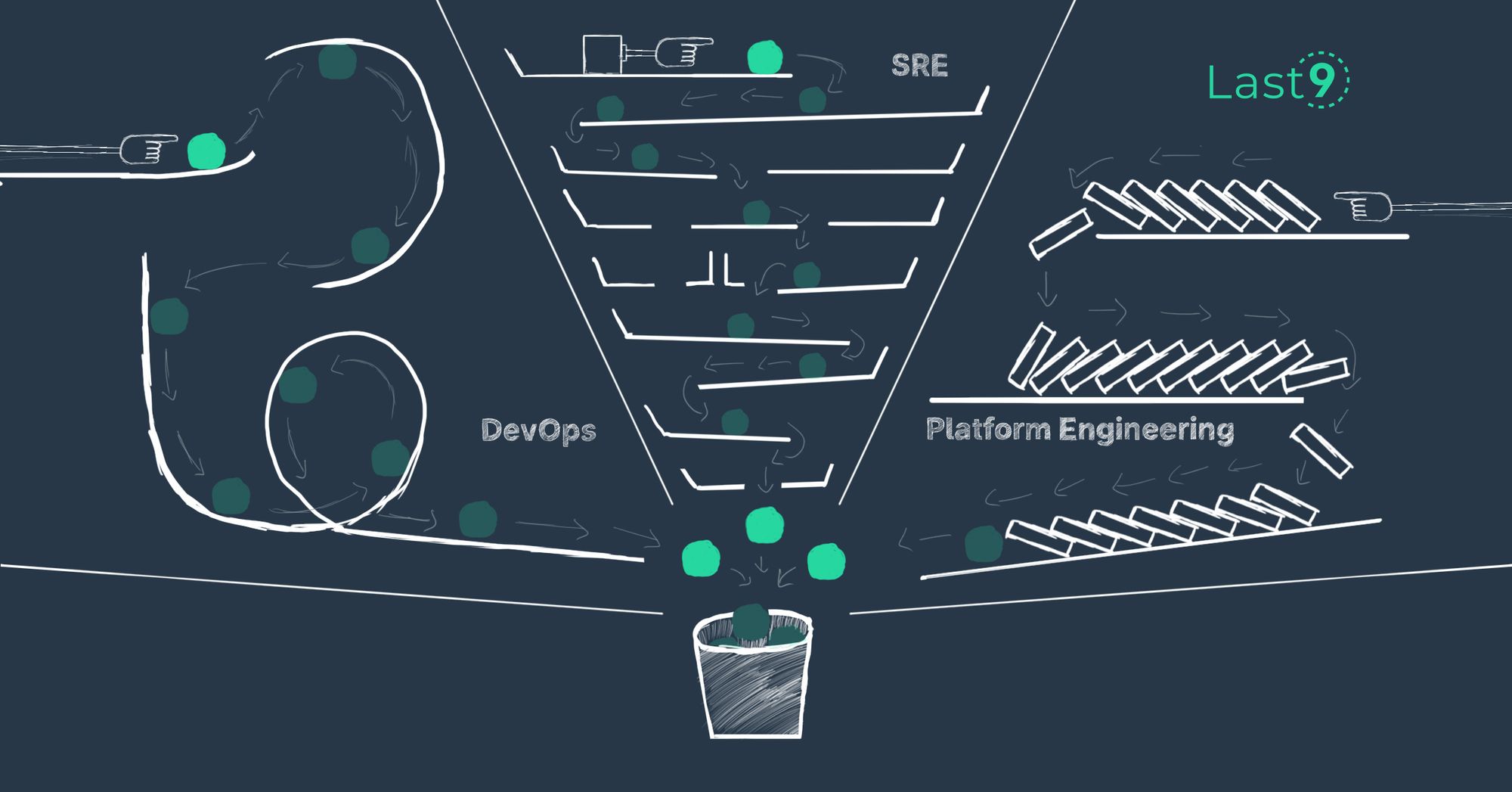
The difference between DevOps, SRE, and Platform Engineering
In reliability engineering, three concepts keep getting talked about - DevOps, SRE and Platform Engineering. How do they differ?
Prathamesh Sonpatki
How to improve Prometheus remote write performance at scale
Deep dive into how to improve the performance of Prometheus Remote Write at Scale based on real-life experiences
Saurabh Hirani
India vs Pakistan, Site Reliability Engineering, and Shannon Limit
How does one ‘detect change’ in a complex infrastructure, so you don’t lose out on critical revenues — A short SRE story
Satyajeet Jadhav
Challenges of Distributed Tracing
What are the challenges, benefits and use cases of distributed tracing?
Last9
Why MTTR should be a ‘business’ metric
One of the many pitfalls of friction between engineering and business is the lack of fundamental measurements on the health of engineering. But how does business measure engineering efficacy, and how does engineering posit its standing to business?
Sidu Ponnappa

Sample vs Metrics vs Cardinality
When dealing with Time Series databases, I always got confused with Sample vs Metrics vs Cardinality. Here’s an explanation as I have understood it.
Piyush Verma

Comparing Popular Time Series Databases
A comparison of all the popular time series databases. Prometheus, Influx, M3Db, Levitate.
Abhi Puranam

Latency is the new downtime
In the early days of Google, a lot of users were asking for 30 results on the first page of search results. So after long deliberation, Marissa Mayer, then the Product Manager for google.com, decided to run the A/B test for ten vs 30 results. When the results came in, they were in for a surprise.
Sahil Khan

We’ve raised a $11M Series A led by Sequoia Capital India!
Change is the only constant in a cloud environment. The number of microservices is constantly growing, and each is being deployed several times a day or week, all hosted on ephemeral servers. A typical customer request depends on at least three internal and one external service. It’s a densely connected web of systems. Any change in such a connected system usually introduces a ripple. It’s tough to understand these impacts. Alert fatigue, tribal knowledge of failures, and manual correlation acro
Nishant Modak
Why Service Level Objectives?
Understanding how to measure the health of your servcie, benefits of using SLOs, how to set compliances and much more...
Piyush Verma

The origin of Service Level Objectives
An obscure term - Service Level Objectives - rules the Software industry. But where does it come from? Strap on your seat belts, this is going to be a bumpy one (pun intended :p)
Akshay Chugh, Piyush Verma

Doing SRE the Right Way!
A well-thought-out approach to SRE, which will help site reliability engineers and software engineers develop and maintain a useful, consistent, and effective SRE strategy for their products!
Piyush Verma

SLOs eased
You can either love running or hate running, but you will definitely love this analogy - take a fresh look at SLOs!
Piyush Verma, Saurabh Hirani

Latency SLO
How do you set Latency based alerts? The most common measurement is a percentile-based expression like: 95% of the requests must complete within 350ms. But is it as simple?
Piyush Verma

Services; not Server
Gone are the days of yore when we named are our servers Etsy, Betsy, and Momo, fed them fish, and cleaned their poop.
Nishant Modak, Piyush Verma

Systems Observability
Observability is not just about being able to ask questions to your systems. It's also about getting those answers in minutes and not hours.
Nishant Modak, Piyush Verma