Jul 23rd, ‘21/5 min read
Services; not Server
Gone are the days of yore when we named are our servers Etsy, Betsy, and Momo, fed them fish, and cleaned their poop.

Cattle; not Kittens
The Internet and Pets have an old relationship. It started with the infamous Pets.com. While unfortunately, the business crashed, and so did the economy, it established that online was here to stay. The economy resurrected, and so did the need for the Internet, stronger than before.

To run a business online, we used to buy server hardware for operations. We named these with respect—animals, dragons, star wars, wines, or movie characters. Just like our pets, we attended to them with care and understood all their quirks.
Fast forward to today, Infrastructure is overwhelmed with pets again. This time around, we are exchanging pet photos and not pet supplies. Suddenly, we have a flock of these servers at our disposal. No longer can we name them after pets, and we care less about the tricks they could do for us. No matter if one fails, there is another one waiting to entertain the load.
What is a Service?
As the scale evolved, the rise of SOA (Service-oriented architectures) was inevitable.
It is unacceptable for an entire factory to be shut for maintenance work on a conveyor belt. Likewise, it is intolerable for software as a whole to be unserviceable in the event of maintenance on a few parts of it. So the simple solution was to split the software into more minor, independent services.
So how would you define a Service?
Is it a group of Endpoints?
Combination of endpoints that fall under the purview of a payment team
Is it a group of Workflow?
A piece of code catering to the Reconciliation workflow
Is it a particular deployment?
A demographic-based Personal Information Collector.
Or shared components serving multiple teams?
A data warehouse, catering to the API and Billing teams
Is it a combination of all of the above?
The chances are that you will choose A combination of all of the above
Establishing Service KPIs
A distributed system is one in which the failure of a computer you didn't even know existed can render your own computer unusable.
The definition of a Service manifests from the definition of failure. An Ideal ask from a software module is that they should be independent and not fail while other modules may fail, but in reality, most resources end up cascading/failing together.
This degree of freedom to continue to operate even when others fail requires
- Dedicated caretakers and components.
- Dedicated release plan.
- Branch logic to handle failure in dependencies.
- Significantly increased coordination to check others’ status
- Specific and establishing contracts of communication
An ideal software should behave almost like a human body. Multiple moving parts are functioning independently with explicit communication contracts, enjoying the same degree of freedom that a Software aspires.
The definition of failure is not a boolean Yes or a No. Instead, there is a period of degraded performance before something is considered broken down. Therefore, for KPIs to be most effective, they should be defined for the Service as a whole. Example: For KPIs of a media streaming service, ProcessingLag is way more effective than CPU utilization.
Here’s an example of some common KPIs that are relevant based on the type of Service.
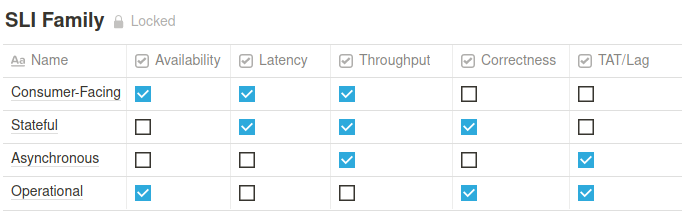
The testament to monitoring Key Performance Indicators of a Service lies in the fact that the best KPIs and monitoring require the slightest inspection of failures. But, instead, it is used to establish other broken parts of the system.
A fair distinction between code vs. service is that a service should only come to meaning when deployed and running. Thus, it would be futile to establish Service Level Objectives for a piece of software that continues to reside in Github and has never been deployed. Different installations of the same service are served with the same KPIs but with different thresholds.
Features vs. Stability

KPIs allow tying all components and parts that fall under the purview of a Service to be observed together. It allows you not to have throw-over-the-wall alerts, which have little or no bearing on the actual health.
Here’s an example: A disk consuming 100% at 3 AM may or may not be actionable depending on its impact on service KPI. For instance, if it’s a logout service and the KPI says 99.999% availability despite a disk failure, It can wait till the morning.
Such correlation of actual metrics to Services and their health allows for the most fundamental decision to be made; Should the next sprint be towards features or stability? Reliability is not a war-time reaction; it’s a peace-time preparation.
This preparation comes at the cost of feature development. If a service has been serving 99.99% of requests without errors and within 20ms for over a month, it can afford a bit of creativity towards new features, which will always present a risk of bringing down the reliability numbers. On the contrary, a service performing too poorly must strengthen the existing deployments ahead of new features.
Cascading
In a microservices/service-oriented architecture, it is essential to identify;
- What is impacting this Service?
- What is this Service impacting?
Once the thought process has moved away from Servers and Components to Service under the impact, it can unlock tremendous gains when coupled with dependency information.
- It allows speedy decision-making because the on-call marshal can engage the right team in case of an Impact.
- When these 9's are counted by the minute, quick detection of upstream and downstream services can bring down the Mean Time to Detect (MTTD) to under single-digit minutes.
- Before one realizes it, The discussion moves from DevOps vs. Code or Infra vs. Testing to "Payment provider X is degrading, let's disable UPI in favor or card to prevent checkout frustrations."
This ability improves the agility and confidence of releasing new features into your product. So next time you see an alert that says Kafka OfflinePartitionsCount has increased, just set them straight by asking what service KPI is being impacted and by how much. In this case, what is the increase in processing Lag for what topic, and lastly, will this alert impact what Service’s freshness?
The fundamental difference that makes Software business so successful, compared with physical counterparts, is the speed of change.
When you start observing every failure correlated with consumer experience, everything that was just data becomes actionable knowledge. The power of knowledge and knowing the earlier unknown allows us to make changes confidently and reliably. You stop caring about the individuality of the underlying components as long as the product isn’t complaining. The underlying components become the cattle, and the services become the new Pet that you tend to with your utmost care. This unconditional care for services is the crux of software reliability!
Last9 is a platform for Software reliability that allows you to view your software as Services-first. It encourages you to pay more attention to Service KPIs, also referred to as Service Level Indicators (SLIs), instead of individual metrics fragmented as business metrics, performance metrics, or Infrastructure. By overall reduction in MTTD and alert fatigue, the end winner is your customer.
I leave you with an Imagination; Next time you are about to make a database change at 3 AM, imagine being able to perform the migration with a clear understanding of how much and where all the impact of that minor downtime will be!
Contents
Newsletter
Stay updated on the latest from Last9.
Handcrafted Related Posts

Getting the big picture with Log Analysis
How to get the most out of your logs!
Jayesh Bapu Ahire

What is MTBI?
Everything you need to know about Mean Time Between Incidents (MTBI) and how it can help Site Reliability Engineers
Last9
Much That We Have Gotten Wrong About SRE
An illustrated summary of Developers ➡ DevOps ➡ SRE
Piyush Verma