Feb 11th, ‘22/7 min read
Doing SRE the Right Way!
A well-thought-out approach to SRE, which will help site reliability engineers and software engineers develop and maintain a useful, consistent, and effective SRE strategy for their products!

About two years ago, I spoke at Rootconf about doing Site Reliability Engineering the right way -
Many companies were starting to understand the DevOps and SRE space at the time, and many are still going through that journey. In the last two years, the software reliability space has matured, with improvements to existing tools and new, innovative tools entering the scene to help engineers build observability into their applications to achieve greater availability and reliability.
Much clarity has also been attained as to what the role of an SRE looks like and how businesses can make the most out of the wonderful world of telemetry, logs, and metrics—although SRE is certainly not limited to these things. The building of increasingly actionable observability is one of the main functions of SRE. Apart from that, it also shares many traditional DevOps functions, including writing software to make lives easier for your developers, investigating incidents, and much more.
This article will take you through a well-thought-out approach to SRE, which will help site reliability engineers and software engineers develop and maintain a useful, consistent, and effective SRE strategy for their products. Let’s dive right in.
Building an Effective SRE Strategy
As software evolves, it is bound to carry more bugs over time. Therefore, the number of code-based failures will also increase with time, not to mention other factors like network and infrastructure. Having a good and effective strategy to mitigate and minimize these problems is at the core of the philosophy behind SRE!
An effective SRE strategy will be more proactive than reactive, more data-driven than anecdotal, and highly accountable. This means that you should take the approach that product managers take for developing products, rather than the approach software operations people take for managing day-to-day incidents and failures.

If you don’t have an effective SRE strategy in place, you’ll probably be making decisions on the fly without much insight into the problem—and you’ll possibly end up introducing more failures into your system than you solved.
So how do you build a good SRE strategy?
Let’s explore some key points that contribute to an effective strategy.
Understand the Cost of Reliability
The SRE journey starts by understanding that 100 percent reliability is a myth, and therefore, downtime is inevitable. The whole point of SRE is first to acknowledge that systems will fail but also that failures don’t have to be catastrophic. You can build fault-tolerance systems, and they can exhibit very fast and effective recovery from failures.
Obviously, enabling SRE for your business increases the cost of tech operations. Still, at that cost, it will also reduce the probability of a catastrophic failure and ensure the graceful operation of your software even with all kinds of network, infrastructure, and API failures.
Get Buy-In from Your Business
When starting to think about an SRE strategy for your business, buy-in is necessary. Creating a good SRE strategy may involve many organizational changes in terms of processes, team structures, budgeting, and so on. Thus, it’s important to have support from across the business to facilitate the necessary organizational structures and resource commitments.
As the concept of SRE relies mostly on the observability of systems, you’ll also end up seeing your teams being more accountable with all kinds of audit logs and trails at your disposal. Observability of data is invaluable not only for your software to work more smoothly but also for helping detect cybersecurity threats.
Agree to Service Levels
Once there is buy-in from the business, a good next step would be deciding what metrics to observe and what failure rates are acceptable. A metric you observe is called a service level. The range of values for that service level is captured using a service level indicator (SLI). Then, service level objectives (SLOs) capture the target values you aim to achieve for these service levels.

Notice that the above SLO examples cover the service level for uptime/downtime, HTTP request success and failures, health checks, API response times, and more. Although there is some consensus over what range these numbers should lie in, these might vary from one application to another.
Follow Our SRE Recipe
After setting SLOs for your business, you need to start implementing the tools and processes necessary to achieve the objectives. SRE starts with the ability to observe what’s happening with any component of your application, servers, databases, and so forth at any given moment; but it doesn’t end there. SRE is also about control. You need to build control into your application so that the observability data is continuous and consistent.
Observability, control, and consistency cannot be achieved when different people manually work on going through logs and running commands to fix broken systems. SRE thrives on automation. Whether it is tracking metrics or taking action based on the breach of a metric, or whether we are talking about centralized log collection or aggregating analysis of slow SQL queries, automation is at the center of it all. It helps with analyzing failure more easily and consistently. Although SRE implementations differ from one company to another, here’s a taste of what it could be like for you:

Invest in Good Documentation
However, observability and automation aren’t really enough on their own. At the end of the day, it is still a human who will look at the code for fixes. It will also be a human doing the maintenance of the SRE code base. For that reason, it is useful to invest in good documentation covering all tech and non-tech topics for SRE, ranging from onboarding, tech stack, architecture, flow diagrams, and more. Documentation about what to do in common failure scenarios will also prove extremely useful.
The technical documentation should be accompanied by clear business documentation that covers the expectation of the business around each role, including processes around cybersecurity, compliance, audits, and many other things. Good documentation may actually make the difference between an hour of downtime and just a few minutes. While downtime is inevitable, efforts to minimize it are critical.
Incrementally Improve Reliability
You can’t expect to achieve reliability just by introducing a set of tools and practices over a short period of time. Instead, it needs to be a carefully planned, incremental process, best implemented as a part of sprints.
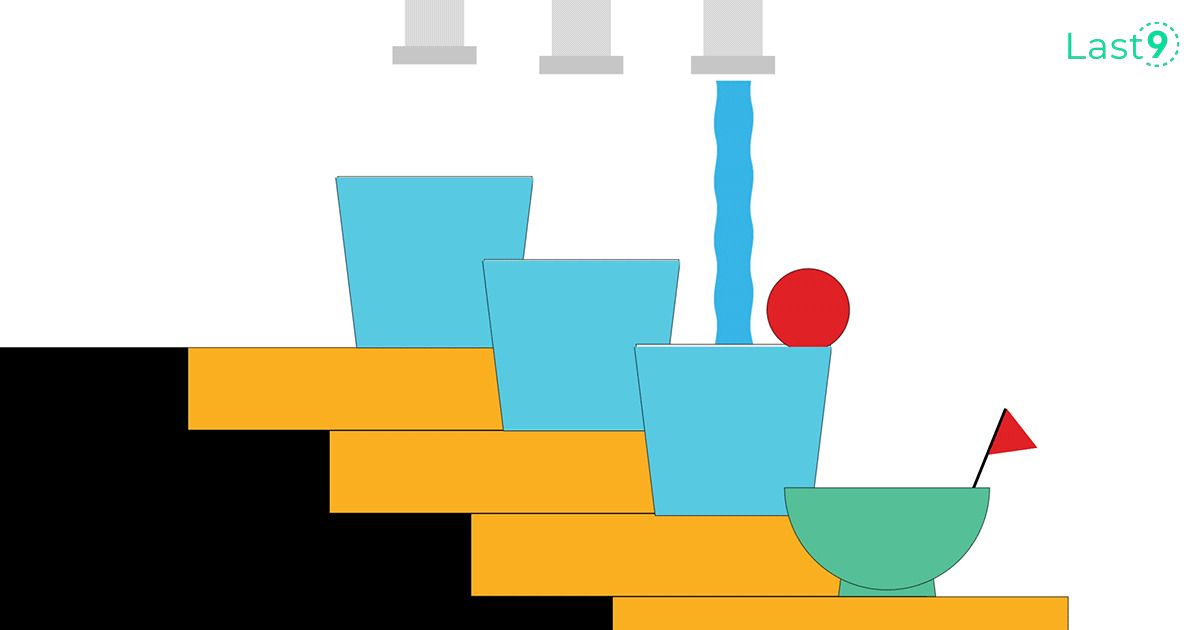
Consider a multi-tiered SRE approach as shown in the image below -

This is a good representation of how the cumulative time of your SRE team should be divided. After putting observability in place for your applications, let the automation work its magic and focus on improvements and new projects. Always keep service and on-call time separate from business-as-usual development. Once the SRE practice is mature enough, integrate services and reuse the tools and practices for SRE in other areas.
Automation Is Absolutely Essential
Automation is the central principle that drives SRE and allows engineers to focus on more subjective and creative problem-solving while letting the tools observe the applications to help the engineers do their jobs better.
The idea that automation is absolutely essential also ties back to the importance of getting your business’s buy-in. The business needs to understand the drastic positive impact of automation on performance and cost. Servers can scale; people cannot.
Frequently Assess Your SRE Maturity
Finally, after building your SRE strategy, you will need to monitor the progress of the implementation and frequently assess your progress in the journey. Extending the concept of several nines to SRE maturity, here are the four levels you can categorize your progress:

Achieving SRE success doesn’t happen overnight. You should not attempt to make your applications have a five-nines availability and reliability straight away; rather, you should create your SRE setup in increments, considering changing business requirements, considering the tech stack, creating better documentation, and understanding the end-user experience better.
Conclusion
SRE is becoming an increasingly essential area for creating and running any piece of software at scale. Companies that care about customer experience will have to invest the tools, technologies, processes, and people in implementing SRE to build observability and reliability into their systems.
In this article, you learned how to get started with SRE, from the business buy-in to strategy implementation. You also learned about the typical steps of the SRE journey, along with some ideas about the different ways to approach the reliability and observability problem.
SRE is all about removing manual effort from incident investigations, root-cause analysis, dashboards, and so on.
Efficiently putting systems—rather than people—in charge of continuously analyzing telemetry and log data enables a smoother, more reliable operation of your applications.
(A big thank you to Kovid Rathee for his contribution to this article)
Contents
Newsletter
Stay updated on the latest from Last9.
Handcrafted Related Posts

Thanos vs. VictoriaMetrics
A deep dive comparison between Thanos and VictoriaMetrics: Performance and Differences
Last9
SLA vs SLO vs SLI - What's the difference
What's the difference between SLAs vs SLOs vs SLIs. Understanding these little nuances are critical for DevOps folks. Here's a simple reckoner on what each of these mean
Last9

Microservices - Tracking Dependencies
Quick primer into microservices architecture and the importance of tracking dependencies
Akshay Chugh, Jayesh Bapu Ahire